✅ 파레토의 법칙

- 사회에서 일어나는 현상의 80%는 20%의 원인으로 인해 발생된다.
- 인터넷 통신의 80%가 20%의 사이트에 대한 액세스로 추정되며, 이 20%의 웹사이트 데이터를 캐시해두면 효율을 극적으로 향상할 수 있다.
✅ 캐시란?
- 데이터의 원래 소스보다 더 빠르고 효율적으로 엑세스할 수 있는 임시 데이터 저장소
- 캐싱 저장소는 원본보다 빠른 접근 속도를 가진다.
- 사용되었던 데이터는 다시 사용되어질 가능성이 높다는 개념 을 이용하여, 다시 사용될 확률이 높은 것은 더 빠르게 접근 가능한 저장소를 사용한다는 개념
✅ 사용하면 좋은 경우
- 단순한 데이터
- 동일한 데이터를 반복적으로 제공해야하는 경우 (자주 조회되는 데이터)
- 데이터의 변경주기가 빈번하지 않고, 단위 처리 시간이 오래걸리는 경우 (데이터 갱신으로 인해 DB와 불일치가 발생할 수 있기 때문)
- 데이터의 최신화가 반드시 실시간으로 이뤄지지 않아도 서비스 품질에 영향을 거의 주지 않는 데이터
✅ 장점
- 서버간 불필요한 트래픽을 줄일 수 있으며, 웹 어플리케이션 서버의 부하가 감소된다.
- 캐시에 저장된 데이터를 빠르게 읽어와 어플리케이션을 사용하는 고객에게 쾌적한 서비스 경험을 제공할 수 있다.
✅ 캐싱 종류
📌 데이터베이스 캐싱
- 데이터베이스 쿼리는 데이터베이스 서버에서 수행되기 때문에 속도가 느려지고 부하가 몰릴 수 있다.
- 결과값을 데이터베이스에 캐싱함으로써 응답 시간을 향상시킬 수 있다.
- 대다수의 데이터베이스 서버는 최적화된 캐싱을 위한 기능을 기본적으로 지원한다.
📌 응답 캐싱
- 웹 서버의 응답을 메모리에 캐싱한다.
- 애플리케이션 캐시는 로컬 인메모리에 저장되거나(로컬 캐싱) 캐시 서버위에서 실행되는 인메모리 데이터베이스(글로벌 캐싱 ex. Memcached, Redis)에 저장할 수 있다.

📌 HTTP 헤더를 통한 브라우저 캐싱
- 모든 브라우저는 HTML, JS, CSS, 이미지와 같은 파일들을 임시 저장을 위해 HTTP 캐시의 구현을 제공하고 있다.
✅ 응답 캐싱
📌 Local Cache
- 로컬 장비 내에서만 사용되는 캐시 → Local 장비의 Resource를 이용한다 (Memory, Disk)
장점
- Local에서 작동 되기 때문에 속도가 빠르다.
- 네트워크 지연, 단절 이슈에 자유로움
- 서버 어플리케이션과 라이프 사이클을 같이 하므로 사용하기 간편함
- 아주 간단한 캐시 등은 메모리 기반으로 동작하는 것이 효율적일 수 있음.
단점
- 휘발성 메모리 → 애플리케이션이 다운되면, 메모리 데이터는 사라짐
- 서버간의 데이터 불일치 (여러 서버에서의 메모리 캐시가 일치하지 않는 현상)
- 애플리케이션의 메모리가 부족해지는 현상 (서버를 스케일 업 해야함)
📌 Global Cache
- 여러 서버에서 Cache Server에 접근하여 사용하는 캐시
장점
- 데이터를 분산하여 저장할 수 있다.
- Replication - 데이터를 복제
- Sharding - 데이터를 분산하여 저장
- 별도의 Cache Server를 이용하기 때문에 서버 간 데이터 공유가 쉽다.
- 확장성이 좋다.
단점
- 네트워크 트래픽으로 인해 Local Cache에 비해 상대적으로 느리다.
- 네트워크 단절 이슈가 있다.
✅ Cache & Data Store 배치 전략 - 읽기
📌 Cache Aside (Look Aside)

장점
- 읽기가 많은 경우 적합
- Cache 서버에 장애가 발생해도 Data Store를 통해 지속 서비스를 할 수 있음
- 반복적으로 동일 쿼리를 수행하는 서비스에 적합
단점
- Cache Store와 Data Store간 정합성 유지 문제가 발생할 수 있음
- 캐시에 데이터가 없는 경우, 더 오랜 시간이 걸리게 된다.
초기에 데이터를 DB에만 저장했다면 처음엔 cache miss가 많기 때문에 성능 저하의 가능성이 있다.
그래서 DB에서 캐시로 data를 미리 넣어주는 Cache Warming 작업을 한다.
📌 Read Through
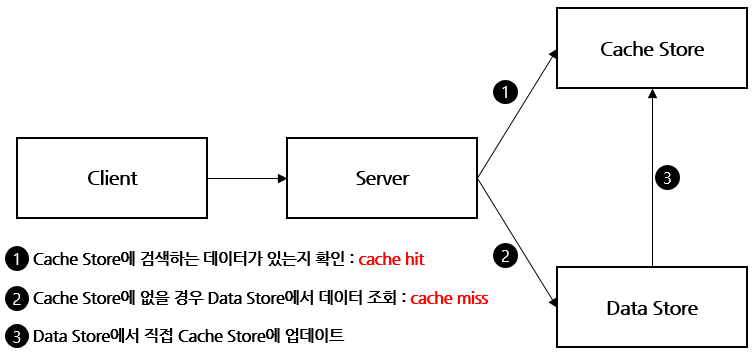
- Cache Store에 저장하는 주체가 Server가 아닌 Data Store인 점에서 Cache Aside 방식과 다르다.
- 초기 데이터는 cache miss가 항상 발생한다는 단점을 커버할 수 있도록 애플리케이션 측면에서 캐시 대상을 판단하여 Data Store 저장(Commit) 시 Cache Store에 Query를 동일하게 수행해 주는 것도 한가지 방안이 될 수 있다.
✅ Cache & Data Store 배치 전략 - 쓰기
📌 Write Back (Write Behind)
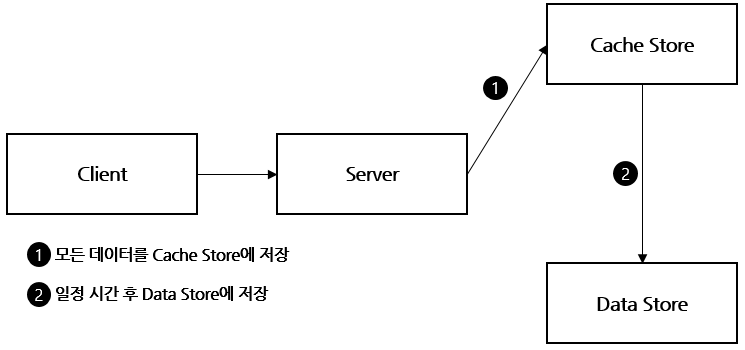
장점
- Cache Store가 데이터 저장소 역할을 하면서 Data Store에 Write 부하를 줄이기 위한 Queue 역할을 겸한다.
- Database의 부하를 경감
- 쓰기 작업이 많은 경우 적용을 권고
- DB의 일시적인 다운타임 허용, 장애 대응 가능
- Cache Store와 Data Store 간의 데이터 정합성을 유지하기에 용이
단점
- Cache Store에서 Data Store로 데이터를 전송하기 전에 장애가 발생하면 데이터 분실 발생 위험이 있음
- 자주 사용되지 않는 데이터가 저장되어 리소스 낭비와 Write 작업 부하 발생할 수 있음 → 이를 해결하기 위해 TTL을 사용하여 사용되지 않는 데이터를 삭제
📌 Write Through
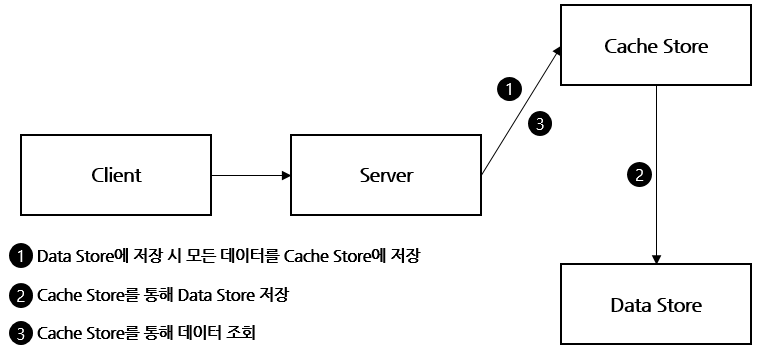
- Write Back은 Cache Store에 저장 후 일정 시간을 두고 나중에 한꺼번에 Data Store에 저장하지만 Write Through는 Cache Store와 Data Store에 매번 저장한다.
장점
- 항상 동기화 되어 있어 항상 최신 정보를 가지고 있다
단점
- 저장할 때마다 2단계 과정을 거치기 때문에 상대적으로 느리다
- 무조건 일단 Cache Store에 저장하기 때문에 캐시에 넣은 데이터를 저장만 하고 사용하지 않을 가능성이 있어서 리소스 낭비 → 이를 해결하기 위해 마찬가지로 TTL을 사용하여 사용되지 않는 데이터를 삭제
📌 Write Around

- 읽은 데이터만 캐시에 저장
- Write Through 보다 훨씬 빠름
- 데이터 정합성 문제 발생
Write-Around는 Read-Through와 결합 될 수 있으며, Cache-Aside와도 결합될 수 있다.
데이터가 한 번 쓰여지고, 덜 자주 읽히거나 읽지 않는 상황에서 좋은 성능을 제공한다.
예를들어, 실시간 로그 또는 채팅방 메시지로 사용 될 수 있다.
Source
https://www.youtube.com/watch?v=92NizoBL4uA
https://meetup.toast.com/posts/224
개발자를 위한 레디스 튜토리얼 01 : NHN Cloud Meetup
레디스는 오픈소스이고, 다양한 서비스에서 레디스를 자유롭게 사용하고 있습니다. 위의 사진에서 볼 수 있듯이 Airbnb, Uber, Instagram도 레디스를 사용하고 있네요. 핑크다이어리, 토스트파일, 두
meetup.toast.com
https://bcp0109.tistory.com/364
Cache 전략
Overview What is Caching ? 글을 참고하여 캐시 전략에 대해 정리했습니다. 1. Cache 란? 위키 백과에는 이렇게 나와 있습니다. 데이터나 값을 미리 복사해 놓는 임시 장소를 가리킨다. 캐시는 캐시의 접
bcp0109.tistory.com
[REDIS] 📚 캐시(Cache) 설계 전략 지침 총정리
Redis 캐시(Cache) 전략 캐싱 전략은 최근 웹 서비스 환경에서 시스템 성능 향상을 위해 가장 중요한 기술이다. 캐시는 메모리를 사용함으로 디스크 기반 데이터베이스 보다 훨씬 빠르게 데이터를
inpa.tistory.com
https://waspro.tistory.com/697
Redis5 설계하기 총정리
개요 이번 포스팅에서는 Redis를 효과적으로 구축/운영하기 위한 설계방법에 대해 알아보도록 하자. Redis는 대표적인 In-memory DB로 세션, 캐시, 큐 등으로 활용된다. 단일 환경으로 가볍게 구성이
waspro.tistory.com
https://wnsgml972.github.io/database/2020/12/13/Caching/
Caching 전략 소개 및 사용 예제
캐싱 전략이란? “캐싱 전략”은 최근 웹 서비스 환경에서 시스템 성능 향상을 위해 가장 중요한 기술입니다. 캐시는 메모리를 사용함으로 디스크 기반 데이터베이스 보다 훨씬 빠르게 데이터
wnsgml972.github.io